自前のMask画像からCOCO format jsonを作成
手作業でAnnotationなんてやってられるか!!!
ということで、画像処理でcoco formatのjsonを作るscriptを書きました。
簡易的なのでぜひ改造して使ってください。
ただしMask情報が二値化画像で取得できている前提です。
そもそも二値化できるなら物体検出いらないというツッコミはさておき…

Mask R-CNN
機械学習において最も注目されている分野の一つが物体検出です。
自動運転や監視カメラなど、画像・映像情報から注目したい物体を抽出する技術で直感的かつ応用の幅が広い技術です。
その中でも有名かつ、開発が盛んなのがMask R-CNNと呼ばれる手法です。
論文はこちら
https://arxiv.org/abs/1703.06870
こんな感じで画像中から物体を検出し、それぞれがなんであるかを判断しています。

{kind=link}
開発の歴史はこちらの記事によくまとまっています。
qiita.com
非常に優れた手法ですが、最初からこんな結果が得られるわけではなく、学習が必要です。
機械学習modelは正解の情報を持っている教師データを元に、最適な内部の重みを決定しています。
(機械学習について詳しく知りたい人はこちら。私も超初心者で勉強中です。)
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 斎藤 康毅
https://www.amazon.co.jp/dp/4873117585/ref=cm_sw_r_tw_dp_x_42Y3Fb1GA2SF8
機械学習スタートアップシリーズ これならわかる深層学習入門 (KS情報科学専門書) 瀧 雅人
https://www.amazon.co.jp/dp/4061538284/ref=cm_sw_r_tw_dp_x_e4Y3Fb8MTHZK4
先程の画像のように様々な物体を精度よく検出するためには大量の画像とそれぞれに正解の情報が必要です。
そこでデータセットとして学習および性能検証に用いられるベンチマークがCOCO datasetと呼ばれる巨大なdatasetです。
COCO dataset
"Common Objects in Context" 略してCOCO。
下の画像で示すように様々な画像と物体、それぞれが何であるか記述された正解情報をもっています。

{kind=link}
正解情報を持つjsonはこんな感じ。
https://docs.trainingdata.io/v1.0/Export%20Format/COCO/
{ "info" : info, "images" : [image], "annotations" : [annotation], "licenses" : [license], } info: { "year" : int, "version" : str, "description" : str, "contributor" : str, "url" : str, "date_created" : datetime, } image: { "id" : int, "width" : int, "height" : int, "file_name" : str, "license" : int, "flickr_url" : str, "coco_url" : str, "date_captured" : datetime, } license: { "id" : int, "name" : str, "url" : str, }
このデータセットが基準となるformatをもっていることによって異なるmodelでも性能が比較できるようになっています。
またjsonのformatを揃えることで様々なデータを入れ替えても同じプログラム上で動くようになっています。
しかし、実際自分で使う際には専用の学習データを使って目的に特化したmodelを作成したいものです。
そのためには画像の中の正解情報を取得するAnnotation作業が必須になります。
Annotation作業

めちゃくちゃめんどくさそう…
数枚ならまだしも学習データは数千枚になる場合が多いので手作業でぽちぽちしていると寿命が尽きてしまいます。
複雑な物体に対しては人間の手が必要ですが、簡易的な画像に対しては楽ができるはずです。
画像処理によるcoco format jsonの生成
用意した画像はこちらからダウンロードしました。
https://www.cis.upenn.edu/~jshi/ped_html/PennFudanPed.zip
簡単のため人がひとりしか写っていない画像だけをえらんでいます。
もちろん、複数の場合でもちょっとした改造を加えれば処理が可能です。

Imageとmaskは同じ名前にしています。
┠ images ┃ ┠ 00001.png ┃ ┠ 00002.png ┃ ┠ 00003.png ┃ ┠ 以下略 ┠ masks ┃ ┠ 00001.png ┃ ┠ 00002.png ┃ ┠ 00003.png ┃ ┠ 以下略
import json import collections as cl import numpy as np import matplotlib.pyplot as plt from scipy import ndimage from skimage import measure from skimage.segmentation import clear_border from skimage.filters import threshold_otsu import cv2 import glob import sys import os ### https://qiita.com/harmegiddo/items/da131ae5bcddbbbde41f def info(): tmp = cl.OrderedDict() tmp["description"] = "Test" tmp["url"] = "https://test" tmp["version"] = "0.01" tmp["year"] = 2020 tmp["contributor"] = "salt22g" tmp["data_created"] = "2020/12/20" return tmp def licenses(): tmp = cl.OrderedDict() tmp["id"] = 1 tmp["url"] = "dummy_words" tmp["name"] = "salt22g" return tmp def images(mask_path): tmps = [] files = glob.glob(mask_path + "/*.png") files.sort() for i, file in enumerate(files): img = cv2.imread(file, 0) height, width = img.shape[:3] tmp = cl.OrderedDict() tmp["license"] = 1 tmp["id"] = i tmp["file_name"] = os.path.basename(file) tmp["width"] = width tmp["height"] = height tmp["date_captured"] = "" tmp["coco_url"] = "dummy_words" tmp["flickr_url"] = "dummy_words" tmps.append(tmp) return tmps def annotations(mask_path): tmps = [] files = glob.glob(mask_path + "/*.png") files.sort() for i, file in enumerate(files): img = cv2.imread(file, 0) tmp = cl.OrderedDict() contours = measure.find_contours(img, 0.5) segmentation_list = [] for contour in contours: for a in contour: segmentation_list.append(a[0]) segmentation_list.append(a[1]) mask = np.array(img) obj_ids = np.unique(mask) obj_ids = obj_ids[1:] masks = mask == obj_ids[:, None, None] num_objs = len(obj_ids) boxes = [] for j in range(num_objs): pos = np.where(masks[j]) xmin = np.min(pos[1]) xmax = np.max(pos[1]) ymin = np.min(pos[0]) ymax = np.max(pos[0]) boxes.append([xmin, ymin, xmax, ymax]) tmp_segmentation = cl.OrderedDict() tmp["segmentation"] = [segmentation_list] tmp["id"] = str(i) tmp["image_id"] = i tmp["category_id"] = 1 tmp["area"] = float(boxes[0][3] - boxes[0][1]) * float(boxes[0][2] - boxes[0][0]) tmp["iscrowd"] = 0 tmp["bbox"] = [float(boxes[0][0]), float(boxes[0][1]), float(boxes[0][3] - boxes[0][1]), float(boxes[0][2] - boxes[0][0])] tmps.append(tmp) return tmps def categories(): tmps = [] sup = ["person"] cat = ["person"] for i in range(len(sup)): tmp = cl.OrderedDict() tmp["id"] = i+1 tmp["name"] = cat[i] tmp["supercategory"] = sup[i] tmps.append(tmp) return tmps def main(mask_path, json_name): query_list = ["info", "licenses", "images", "annotations", "categories", "segment_info"] js = cl.OrderedDict() for i in range(len(query_list)): tmp = "" # Info if query_list[i] == "info": tmp = info() # licenses elif query_list[i] == "licenses": tmp = licenses() elif query_list[i] == "images": tmp = images(mask_path) elif query_list[i] == "annotations": tmp = annotations(mask_path) elif query_list[i] == "categories": tmp = categories() # save it js[query_list[i]] = tmp # write fw = open(json_name,'w') json.dump(js,fw,indent=2) args = sys.argv mask_path = args[1] #mask_path = "" json_name = args[2] #json_name = "person_sample.json" if __name__=='__main__': main(mask_path, json_name)
こちらの記事を参考にさせていただきました。ありがとうございました
。
qiita.com
肝となるのはこの部分です。
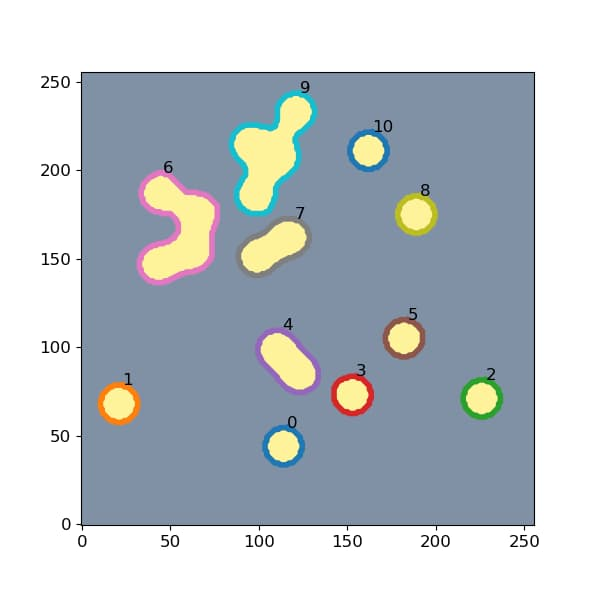
contours = measure.find_contours(img, 0.5)
find_contoursは画像中の物体の輪郭のpix座標を取得してくれます。
また、bboxについては
pos = np.where(masks[j])
この部分で取得したmask情報を持つpixの最大値最小値を使っています。
Mask R-CNNのdemo codeを参考にしています。
pytorch.org
取得したjson fileはこちら。
{ "info": { "description": "Test", "url": "https://test", "version": "0.01", "year": 2020, "contributor": "salt22g", "data_created": "2020/12/20" }, "licenses": { "id": 1, "url": "dummy_words", "name": "salt22g" }, "images": [ { "license": 1, "id": 0, "file_name": "FudanPed00011.png", "width": 459, "height": 420, "date_captured": "", "coco_url": "dummy_words", "flickr_url": "dummy_words" #〜中略〜# ], "annotations": [ { "segmentation": [ [ 48.0, 129.00229357798165, 47.96153846153846, 129.0, 48.0, 128.9878048780488, 48.016129032258064, 129.0, 48.0, #〜中略〜# "id": "0", "image_id": 0, "category_id": 1, "area": 62868.0, "iscrowd": 0, "bbox": [ 36.0, 55.0, 156.0, 403.0 ] }, #〜中略〜# ], "categories": [ { "id": 1, "name": "person", "supercategory": "person" } ], "segment_info": "" }
元の画像とこのjson fileがあればほとんどのCOCOを基準に開発されている物体検出が動くはず。
ではまた。